当ai成为行骗的法宝,我们又该如何辨明真伪
最近,昔日同学在QQ上发来消息,“在干嘛呢”熟悉又俏皮的文字勾起了我高中与她的美好回忆,我立刻回复她。紧接着她问我“你微信可以收款嘛”“我扫微信给你帮忙从QQ发红包给我朋友行吗”我心想,动动手指的小忙,立马就答应了。可没想到……她转了990。我惊讶于数额的庞大,随后,我非常恐慌,因为我发现我根本没有收到这笔钱。我怕她不小心转错账号了,我怕……我谨慎地发信息询问我没收到。“收款时间转的延迟两个小时才到”这一瞬间,我反应过来了,这是诈骗,随后我立马打视频给她,她挂了,但发来了一段视频,是我朋友本人,用熟悉的音色与语调,说着“放心吧,宝子,是我本人”。太像了,我感慨于ai技术的发达。随后她看我迟迟不转账,又发来了一段受伤的视频,这段视频有明显的合成痕迹,我直接揭穿了她。
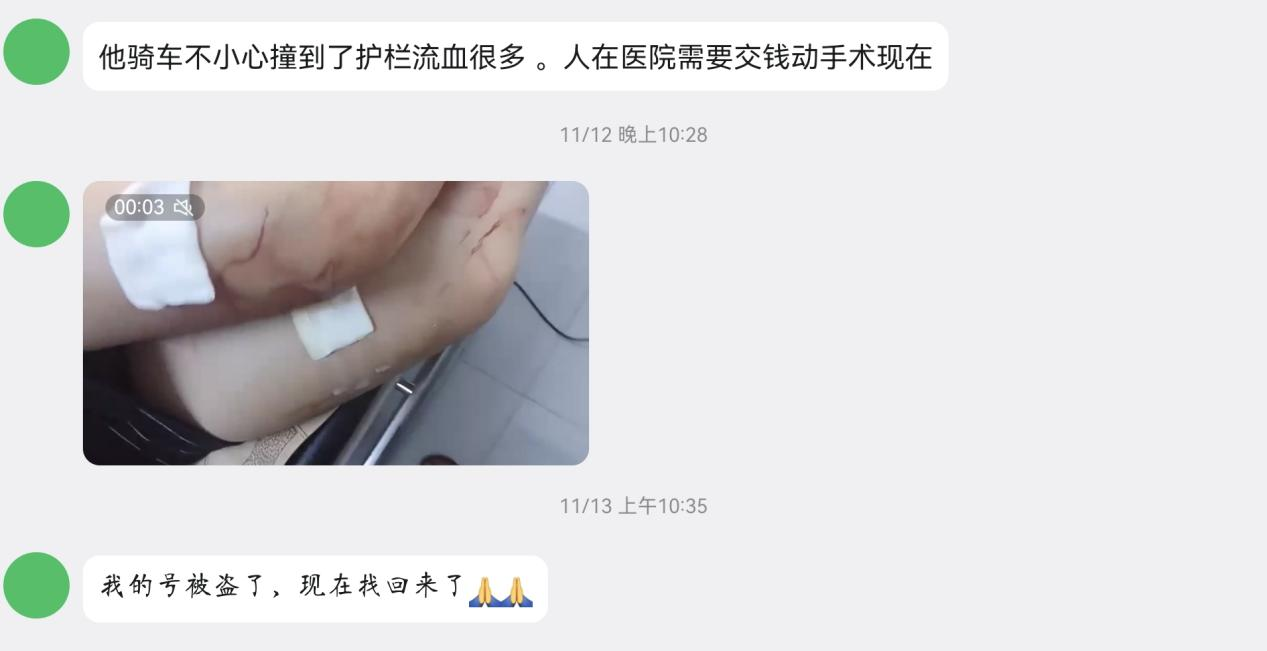
来源:钟莹1
这场骗局让我感受到了ai的恐怖,它的语言克隆技术和视频合成技术非常逼真让人难以一眼分辨真假。我开始去了解ai视频生成的原理。
AI语言克隆技术分三步:
1. 数据采集与预处理:获取目标人物少量语音样本(通常1-3分钟即可),清洗噪音后,拆解为音素(音的最小区别单位如:b、p)、基频(声音的基础振动频率,可以用来区别男女老少)、频谱包络(声音频谱的轮廓形态,区分音色的关键)、韵律(语速/语调/停顿)等核心音色特征,构建专属音色库。
2. 模型训练:用TTS(语音合成)类模型(主流如VITS、FastSpeech2),以目标音色特征为标签,结合海量通用语音数据训练,让模型学习“文本→语音”的映射关系,同时精准复刻目标音色和说话风格。
3. 语音生成:输入任意文本,模型调用已训练好的目标音色参数,合成出与原人物音色、韵律高度一致的语音,实现“文本转目标人声音”的克隆效果。
而AI视频生成分两种
一种是文本生成视频,另一种是人像驱动视频。非常直观,两者天差地别。
前者分三步:
第一步:文本理解。通过大语言模型(LLM)解析文本语义,转化为模型可识别的视觉特征指令(如场景、人物、动作、镜头角度)。
第二步:关键帧生成。用图像生成模型(如扩散模型),基于视觉指令生成视频的核心关键帧(如开头、中间动作转折、结尾),确保画面符合文本描述。
第三步:时序补帧与连贯优化。通过时序建模模型(如3D扩散、光流预测),在关键帧之间补充过渡帧,修正帧间的动作、光影、物体位置偏差,最终输出流畅的完整视频。
后者分两步:
第一步换脸:提取源人脸特征(五官轮廓、皮肤纹理、表情细节)和目标视频的背景、动作特征,用特征匹配与融合模型(如GAN生成对抗网络),将源人脸替换到目标视频的人物脸上,同时适配目标视频的光影、角度变化。
第二步动作驱动:提取驱动视频的人体姿态(骨骼关节位置),映射到源人物图像/视频上,通过姿态迁移模型,让源人物复刻驱动视频的动作,保持源人物的音色、外貌不变。
其实,不管是视频生成还是语言克隆,都需要有数据库的支持。而恰好,现在各大平台都公开或半公开数据,让我们赤裸裸的。我们的隐私变得透明这将是不可避免的,既然改变不了环境,就要改变自身。我们应该学会分辨视频真假,揭露低劣的骗局。
识破AI语言克隆和生成视频关键看这两个信号:细节是否失真、逻辑是否矛盾。
1.抓细节,听语音环境是否有噪音,语速是否自然有音调情绪起伏,内容是否贴近生活。
2.抓逻辑,语句内容前后是否连贯有无重复啰嗦,视频背景是否符合说话内容。
话说回来,其实只要我们多留心眼,与当事人勤核实,再厉害的技术也骗不过清醒的头脑。当骗子用AI克隆企业CFO语音,谎称紧急付货款诱导财务转账198万元,我们牢记“转账先核实”,通过官方渠道确认身份,成功拦截骗局;当骗子伪装“现役军官”处对象,以“内部投资渠道”为诱饵,教唆受害人抵押房产取现20万元,我们保持情感警惕,识破“高回报”谎言,避免财产损失;当骗子冒充电商客服,诱导下载屏幕共享软件窃取银行卡信息,妄图转走5.8万元,我们坚守“官方渠道办业务”原则,拒绝陌生软件,筑牢资金安全防线。
图源:CCTV
那为什么还是有人上当受骗呢?或许骗子的身份也很关键,他们盗用受害者亲人、友人的身份,获取受害者的信任,制造危机的情况让受害者来不及思考,成为骗子的提款机。小编想告诉大家:当收到周围人的求助视频,多停顿几秒辨别一下,这几秒不是冷血,而是冷静,是谨慎,也是智慧。希望朋友们学会在生活中多留几秒。
供稿单位:重庆理工大学计算机科学与工程学院
作者:重庆理工大学 钟莹
审核专家:梁钰霞
声明:除原创内容及特别说明之外,部分图片来源网络,非商业用途,仅作为科普传播素材,版权归原作者所有,若有侵权,请联系删除。

图文简介